VibeVoice-ASR+Gemma4での日本語文字起こし、性能爆上がりだな!
【読むのに約 5 分】
mp4tosrtという自作ツールを作っている。
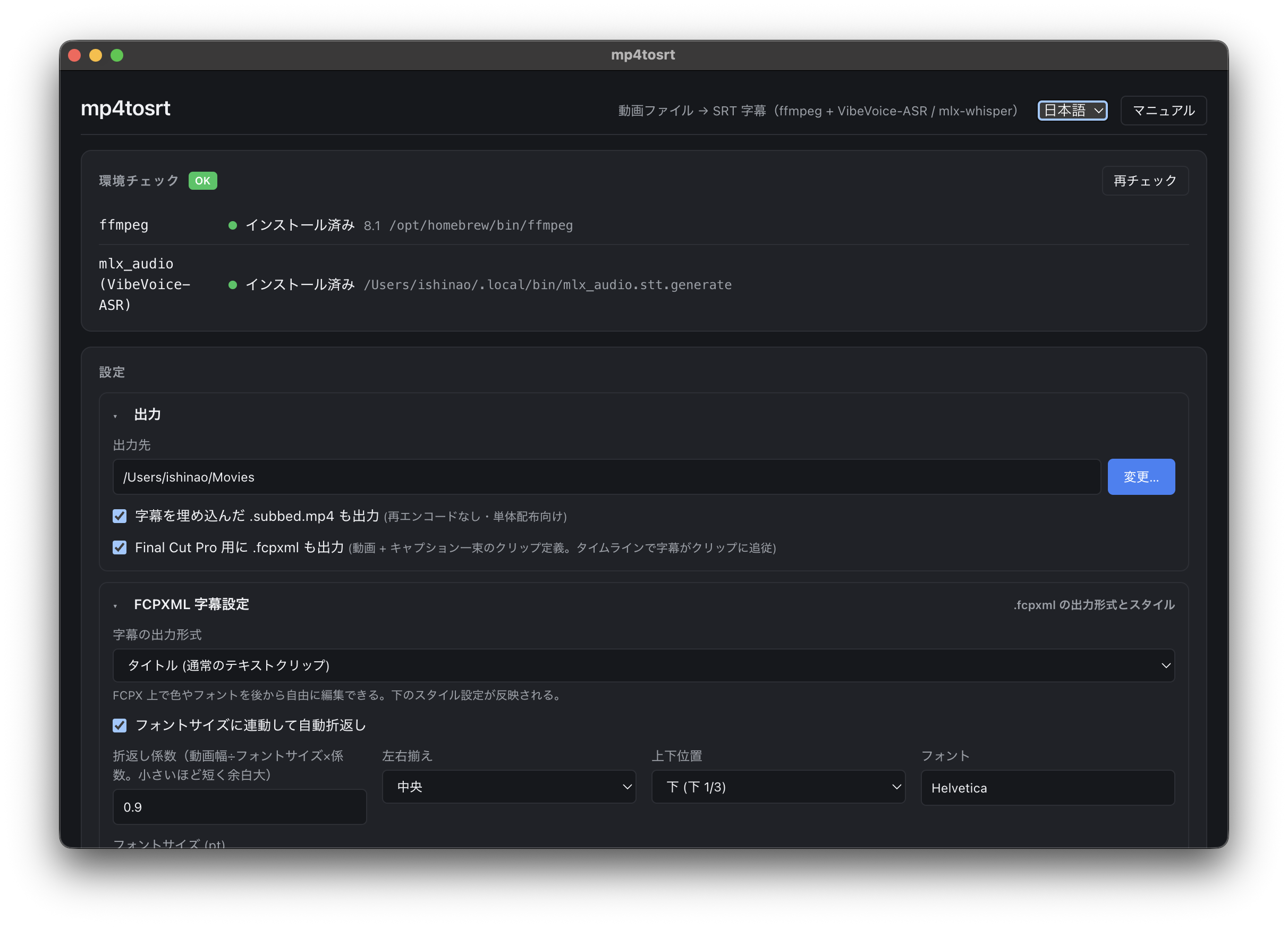
Apple Silicon Mac上で動画ファイルを読み込み、音声を文字起こしして、字幕ファイル形式のSRTやFinal Cut Pro用のFCPXMLを書き出すためのツールだ。必要なら字幕入りMP4も作れる。簡単に言えば、動画に日本語テロップを付ける作業を楽にするためのものだ。
SRTは、字幕ファイルのかなり標準的な形式である。中身はほぼテキストで、字幕番号、表示開始時刻、表示終了時刻、表示する文章が順番に並んでいる。動画編集ソフトやYouTubeなど多くのツールが読み込めるので、文字起こし結果を字幕として受け渡すときの共通フォーマットとして扱いやすい。
ソースコードはheavymoons/mp4tosrtに置いている。配布用のdmg/zipはGitHub Releasesから落とせる。
わたしは普段、動画編集ソフトとしてAppleのFinal Cut Proを使っている。Final Cut Proはよくできたソフトだと思うのだが、英語の文字起こしは結構前にできるようになったのに、日本語にはまだ対応していない。Apple Intelligenceが発表されてからもうだいぶ経つのに。
MacでFinal Cut Proを使って動画編集するときに、気軽に日本語テロップを付けたい。
mp4tosrtに動画を放り込むと、音声抽出、文字起こし、ローカルLLM校正、SRT出力、FCPXML出力、字幕入りMP4生成までをまとめて面倒を見る。画面としてはこんな感じで、ffmpegとVibeVoice-ASRの環境チェック、SRT/FCPXML/字幕入りMP4の出力設定をまとめて扱う。
最初はWhisper + Qwen3.5で作っていた。
Whisperで音声を文字起こしし、そのSRTをQwen3.5 9Bに渡して校正させる。文字起こしエンジンが音として拾ったものを、LLMが文脈を見ながら自然な日本語に直してくれるはず、という設計だ。
発想としては悪くなかったと思う。
ただ、実際にやってみると、期待したほどではなかった。
素のWhisperはこうだった。
それを使ってMacルSiliconMacを上で
日本語対応文字を起こしをした上で
そういうものを補正してできるだけ正しい文字を腰にする
人間だって聞き回すみたいなことを当たり前にやってるような話だと
元の話を知っていれば、なんとなく意味は取れる。Apple Silicon Mac上で日本語の文字起こしをして、できるだけ正しい文字起こしにする。人間だって聞き返すことがある。たぶん、そういうことを言っている。また、このテキストだけでは分からないが、この途中で話したブロックが丸ごと欠けていたりもする。
これをQwen3.5 9Bで校正すると、こうなる。
それを使って Mac の Silicon Mac を上で
日本語対応文字起こしをした上で
そういうものを補正してできるだけ正しい文字を腰にする
人間だって聞き回すみたいなことを当たり前にやってるような話だと
少し良くなる。スペースや表記は整うし、「日本語対応文字を起こし」は「日本語対応文字起こし」になる。ただ、意味として壊れているところはかなり残る。「Mac の Silicon Mac を上で」も変だし、「文字を腰にする」もそのままだ。「聞き回す」も直らない。
Qwen3.5は、ここではちょっと賢い文字列置換に近かった。厳密一致でなくてもそれなりに補正してくれるが、文脈から踏み込んで日本語を組み直すところまではあまり行かない。
同じ箇所をGemma4で校正すると、こうなる。
それを使ってMacやSilicon Macの上で
日本語対応の文字起こしをした上で
そういうものを補正してできるだけ正しい文字に修正する
人間だって聞き返すみたいなことを当たり前にやってるような話だと
これは明らかに一段良い。「日本語対応の文字起こし」「正しい文字に修正する」「聞き返す」あたりは、単なる表記補正ではなく、話の意味を見て直している感じがある。
もちろん、全部が完璧になるわけではない。「MacやSilicon Macの上で」はまだ変だし、Whisperの時点で細切れになっている箇所はGemma4でも救いきれない。入力が壊れすぎていると、LLMだけでは限界がある。
そこでVibeVoice-ASRである。
VibeVoice-ASRをmp4tosrtに組み込んで、同じ動画を文字起こししてみた。
今度は、Whisperの比較で使ったのと同じ箇所を見る。VibeVoice-ASR単体だとこうなる。
それを使って、Mac、シリ、AppleSiliconMacを
上で、日本語対応文字起こしをした上で、えーと、オープンソース、LLMモデル、Qwenとか、Gemmaとか
ああいうものを使って、文字起こしたテキストの補正を行う、校正を行う
文脈に応じた技術用語とか、学術用語とか、あるいは日常会話の固有名称とか、
そういうものを補正して、できるだけ正しい文字起こしにする
人間適当に普段のしゃべりでしゃべってて、聞き取れなかったら聞き返すみたいなことを
当たり前にやってるようなしゃべりだと
これはもう、かなり読める。Whisperでは丸ごと抜けていたオープンLLMモデルの話もきちんと文字起こししてくれているし、部分的にしか拾えていなかったところもかなり正確に出ている。
もちろん粗さはある。Mac、シリ、AppleSiliconMacあたりはまだ整理したいし、固有名称も固有名詞に直したい。ただ、Whisperの「文字を腰にする」や「聞き回す」とは段階が違う。
VibeVoice-ASRは、音を拾って日本語っぽい断片を並べるというより、最初から話の流れとして読める日本語を出してくる。ここが大きい。
ここにQwen3.5 9Bで校正をかけると、細かい表記は少し整う。AppleSiliconMac が Apple Silicon Mac になったり、LLMモデル が LLM モデル になったりする。
実際の抜粋はこうだ。
それを使って、Mac、シリコン、Apple Silicon Mac を
上で、日本語対応文字起こしをした上で、えーと、オープンソース、LLM モデル、Qwen とか、Gemma とか
ああいうものを使って、文字起こしたテキストの補正を行う、校正を行う
文脈に応じた技術用語とか、学術用語とか、あるいは日常会話の固有名称とか、
そういうものを補正して、できるだけ正しい文字起こしにする
実際のところ、人間適当に普段のしゃべりでしゃべってて、聞き取れなかったら聞き返すみたいなことを当たり前にやってるようなしゃべりだと、
そんなにクオリティが高く、文字起こしできるわけがないわけですよね。
ただ、VibeVoice-ASRの出力が最初からかなり読めるので、Qwen3.5による改善幅はそこまで大きくない。
そして、VibeVoice-ASR + Gemma4である。
LLM校正設定では、Gemma 4 12B Q4_K_Mを選び、共通プロンプトやバッチサイズ、文脈に応じたキューマージを設定している。
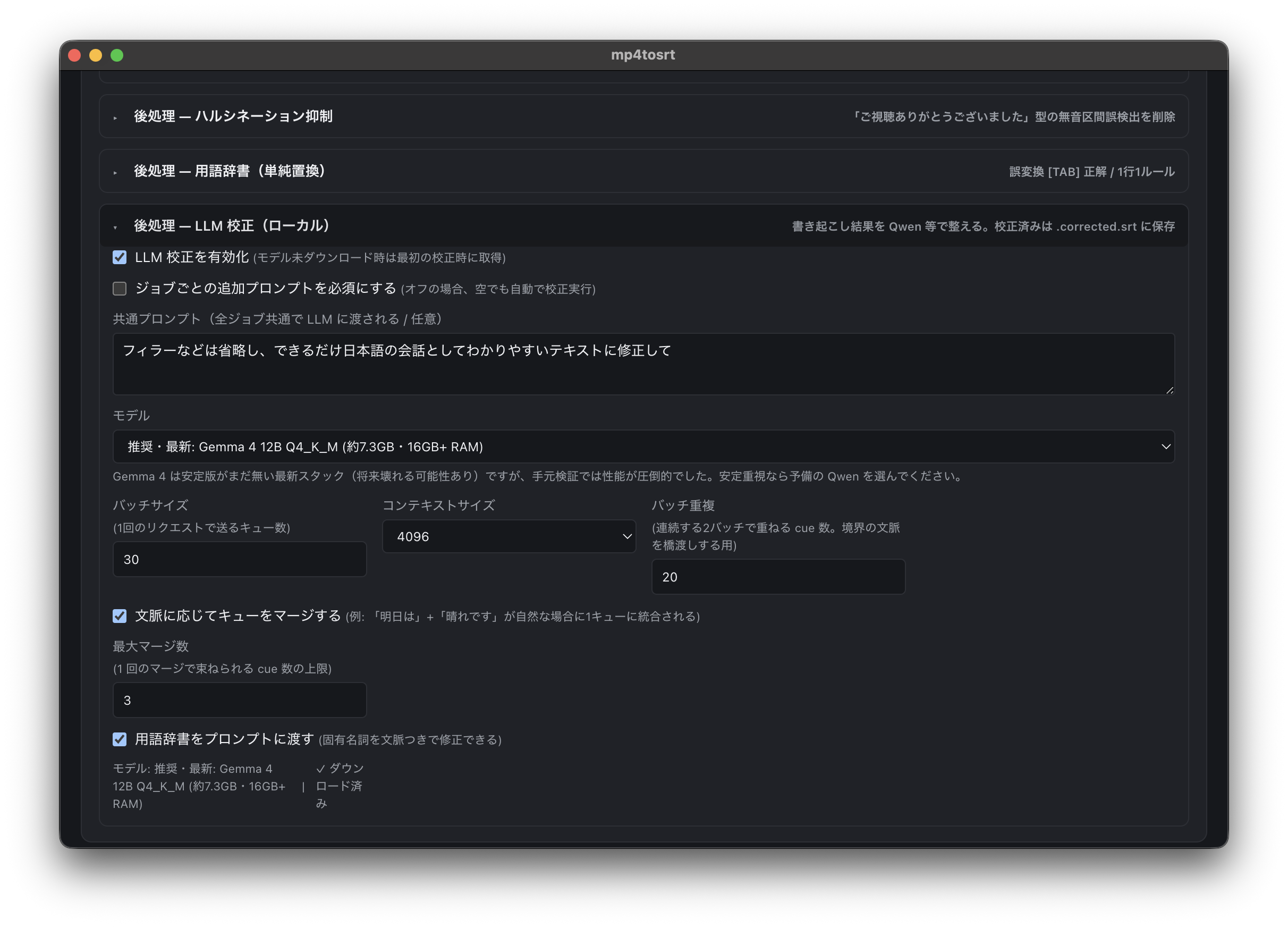
これが一番よかった。
同じ箇所をVibeVoice-ASR + Gemma4で処理すると、こうなる。
それを使って、Mac、Apple Silicon Mac上で、日本語対応文字起こしをした上で、
オープンソースLLMモデル、Qwenとか、Gemmaとか
ああいうものを使って、文字起こしたテキストの補正を行う、校正を行う
文脈に応じた技術用語とか、学術用語とか、あるいは日常会話の固有名称とか、
そういうものを補正して、できるだけ正しい文字起こしにするみたいなことをやる。
実際のところ、人間適当に普段のしゃべりでしゃべってて、
聞き取れなかったら聞き返すみたいなことを当たり前にやってるようなしゃべりだと
これはもう、ほとんどそのまま使える。
Whisper + Qwen3.5やWhisper + Gemma4では、壊れた入力をどうにか救おうとしていた。それを実際に使おうとすると、文字起こし結果を見ながら人間がかなり頑張って直す必要があった。
VibeVoice-ASR + Gemma4だと、最初から下書き字幕として成立している。人間の仕事は、ゼロから書き直すことではなく、最後の調整になる。
これは大きい。
実際に、このVibeVoice-ASRでSRTを出し、Gemma4で校正する版のmp4tosrtで生成した字幕を使って、Final Cut Proから書き出した動画もYouTubeに上げた。
一箇所だけテロップが画面外まではみ出していたので、そこだけFinal Cut Pro上で位置を調整した。それ以外はmp4tosrtの出力のまま載せている。
文字起こし、校正、FCPXML生成まで通した結果をほぼそのまま使っているわけで、これくらい出るなら十分実用的じゃないか、という感じがある。
mp4tosrtでは、VibeVoice-ASRをmlx-audio経由で使っている。実装としては、mlx_audio.stt.generateを呼び出してSRTを作る。モデルはmlx-community/VibeVoice-ASR-4bitを既定にしていて、これは約5.7GBある。高精度版としてbf16も用意しているが、そちらは約16.7GBある。ちょっと重そうなので、まだ試していない。
Gemma4のほうも、足元はまだだいぶアツアツである。
mp4tosrtの内部では、オープンLLMモデルと接続するためにnode-llama-cppを使っている。だが、通常のnode-llama-cppはまだGemma4に正式対応していない。
そこで、scripts/setup-gemma4-llama.mjsという暫定ブリッジを作った。
やっていることはわりと強引だ。
withcatai/node-llama-cppのgilad/gemma4ブランチを固定SHAで取得し、llama.cppのb9524をソースビルドする。それをアプリ側のnode_modules/node-llama-cppに最小コピーで差し替える。さらに、Gemma4非対応の古いprebuiltが選ばれないように、@node-llama-cpp/*も消す。
依存ライブラリを使っています、というより、依存ライブラリのまだマージされていない未来を自分で引っ張ってきて、無理やり現在に差し込んでいます、という状態だ。
VibeVoice-ASRのほうも新しい。音声59分上限のような制約もあるし、今後のアップデートで挙動が変わる可能性はある。
なので、安定動作だけを考えるなら、まだmlx-whisperやQwen3.5を予備として残しておく必要がある。
ただ、配布パッケージとしては、ユーザーに自分の手元でnode-llama-cppのブランチを取ってきて、llama.cppをビルドして、node_modulesを差し替えてください、とは言えない。
さすがにそれは厳しい。
なので、npm run distでは先にsetup:llamaを実行し、そのあとElectronアプリをビルドして、arm64 Mac用のdmg/zipを作るようにしている。未署名アプリなので、初回起動時に隔離属性を外す必要はある。それでも、ユーザーが自分でGemma4対応のnode-llama-cppをビルドするよりは、配布パッケージにこの面倒を押し込んだほうがまだ現実的だ。
まだ作りかけではある。
でも、Whisper + Qwen3.5で「まあ、脳内補正すれば読める」くらいだったものが、VibeVoice-ASR + Gemma4で「このまま下書き字幕として使える」くらいまで来た。
すげー。